The T20 World Cup final delivered everything cricket fans hoped for - pressure, drama, and moments that millions will remember for years. Sanju Samson and Jasprit Bumrah played defining roles, and when the final ball was bowled, India had its champions. But while fans celebrated, another remarkable number quietly told a different story behind the scenes: the match crossed 82 crore total views, with a peak of nearly 6.5 crore concurrent viewers watching live on JioHotstar - 65 million people pressing play at the exact same time.
For the players, the tournament was over. But for another group of professionals - the engineers - the real work was just beginning. Because the Indian Premier League (IPL) is always around the corner, and IPL pushes live streaming infrastructure even harder. Engineers often talk about the "Dhoni spike" - when MS Dhoni walks out to bat and millions of users suddenly open the app within seconds. Add stars like Rohit Sharma and Virat Kohli, weekend double-headers, and high-voltage evening matches, and the pressure on live streaming infrastructure becomes enormous.
That is why DevOps engineers, Site Reliability Engineers (SREs), and system designers begin preparing for the next big event almost immediately. Because when millions open an app to watch a six, a wicket, or the final over, the platform must survive - and that survival is the result of careful System design, cloud infrastructure, CDN architecture, and reliability engineering at internet scale.
Why Live Cricket Streaming Is One of the Hardest Engineering Problems on the Internet
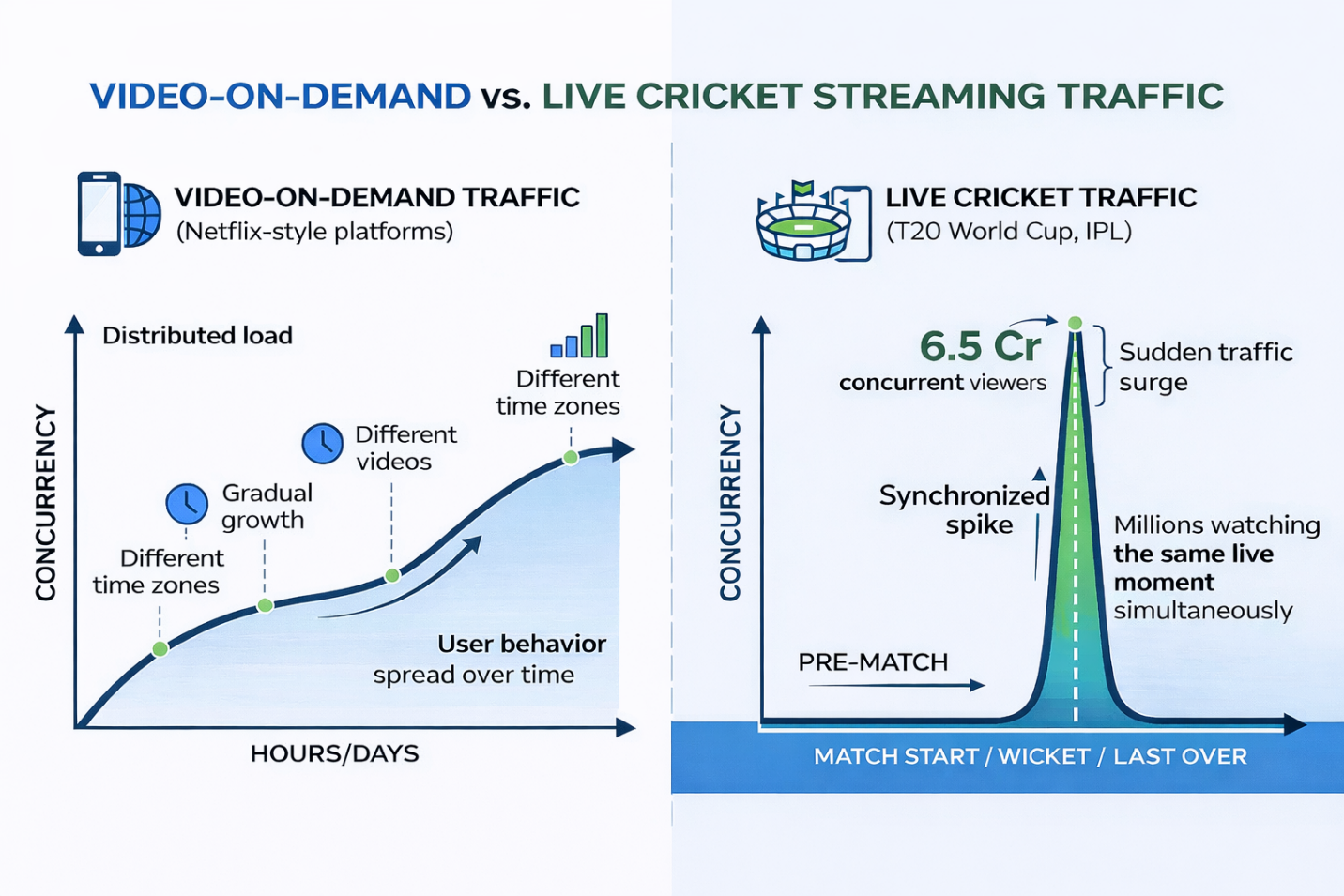
To understand the challenge, compare cricket streaming with other major platforms. Most people assume Netflix or YouTube face the same problems. They operate at enormous scale - but their traffic patterns are fundamentally different. That difference is the key to understanding why live sports streaming requires a completely different system design approach.
How Netflix Streams Video at Global Scale
Netflix serves hundreds of millions of users worldwide under anon-demand traffic model. Users choose what to watch and when. One viewer starts a movie at 8 PM, another watches a documentary at midnight, a third binge-watches a series on Sunday. This naturally distributes traffic across time and content - even a viral new show builds viewership gradually over hours or days, not in a single second.
Netflix addresses this through its proprietary delivery network,Open Connect - thousands of caching appliances embedded inside ISPs worldwide. Popular content is pre-loaded to these appliances, so when a user hits play, the video is served from a nearby edge node rather than a distant data center. Combined with Adaptive Bitrate Streaming (ABR), which dynamically adjusts video quality based on bandwidth, Netflix architecture focuses on content distribution, encoding pipelines, and recommendation systems - not synchronized spikes.
How YouTube Handles Massive Video Traffic
YouTube hosts billions of user-created videos. At any moment, millions of viewers watch entirely different creators and topics. Even viral videos spread their views across minutes or hours - millions of users rarely press play at the exact same second. YouTube therefore optimises for horizontal scalability: distributed storage, global load balancing, and edge caching that scale smoothly as more viewers join, rather than absorbing a sudden synchronized burst.
Why Live Cricket Streaming Is Completely Different
In a live cricket match, millions of viewers watch the exact same video stream at the exact same moment. More critically, they react simultaneously to key events. When a batter hits a six, when a wicket falls, or when the match enters the final over, tens of millions of users simultaneously:
- Refresh the stream
- Reconnect after buffering
- Rewind the previous ball
- Open highlights or scorecards
Engineers call this a
synchronized traffic spike. Unlike Netflix or YouTube traffic which spreads across time, live sports traffic arrives in enormous, near-instantaneous bursts. Handling these bursts requires a completely different
system design philosophy.
Capacity Planning: The Numbers Behind a 6.5 Crore Viewer System
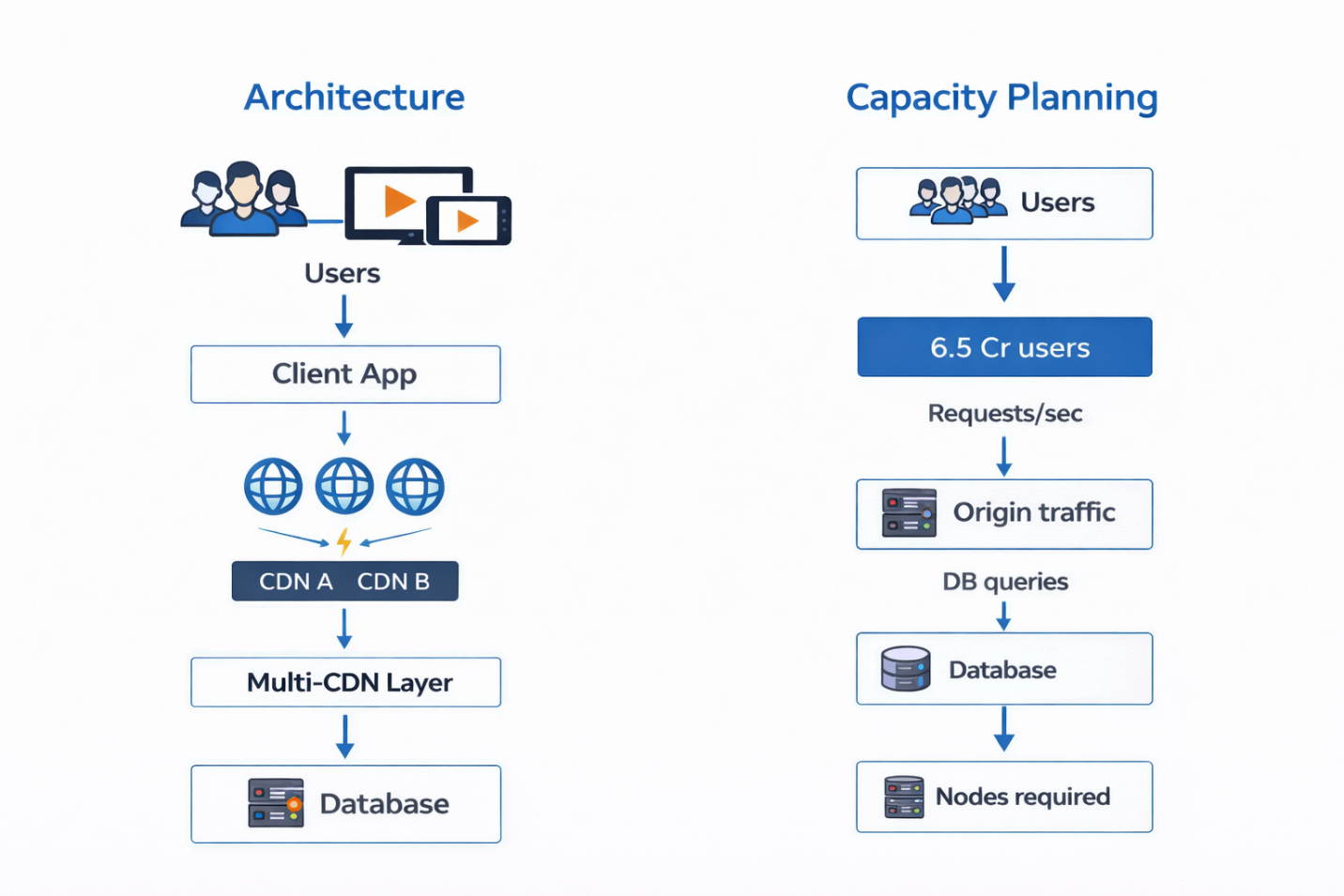
To understand the infrastructure scale, start with the key assumptions. Peak concurrent viewers:
6.5 crore ≈ 65,000,000. Assume 5% of concurrent viewers generate an API request per second during a micro-spike (refreshes, replays, metadata fetches). These are conservative estimates used to illustrate scale.
Scenario A - Worst Case (No CDN Caching) If no CDN cache or edge offload exists:
- Total backend RPS = 65,000,000 × 0.05 = 3,250,000 requests/sec
- If 20% require a DB query → 650,000 DB queries per second
- Most single-region RDBMS clusters cannot sustain this without sharding, multi-region replication, or distributed SQL
This scenario illustrates why
origin protection is not optional - it is mandatory.
Scenario B - Realistic Target with CDN Offload (~90%) With CDN and edge caches serving 90% of requests (realistic for media segments and static assets):
- Origin RPS drops to 325,000 req/sec (3,250,000 × 10%)
- If 10% of origin requests still require a DB hit → ~32,500 DB queries/sec
- Achievable with pre-warmed replicas, aggressive caching, sharding, and async buffering
The Golden Rule: Protect the Origin Server
In large-scale streaming architectures, engineers follow one non-negotiable principle:
Protect the origin servers at all costs. Origin servers handle dynamic processing and database queries. If these systems become overloaded, the entire platform fails.
To prevent this, streaming platforms rely heavily on
Content Delivery Networks (CDNs).The Role of CDNs in Large-Scale Streaming A CDN is a distributed network of servers placed around the world. These servers cache frequently requested content such as:
- Video segments
- Thumbnails
- Metadata
- Static files
When a user requests a video segment, the CDN serves the content directly from a nearby edge location rather than forwarding the request to the origin server.
The goal is simple:
Serve more than 90% of requests directly from CDN caches.If CDN handles 90% of the traffic *, the load on backend infrastructure drops dramatically. Let’s apply that to our earlier example. If the platform receives
3.25 million requests per second, and CDN handles 90% of them, the origin servers receive only:
325,000 requests per secondThis reduction is the difference between a system surviving and collapsing.
* Clarification on the 90% target. When practitioners cite “90%+ cache hits,” they typically refer to media segments and static assets (video chunks, manifests, images). Personalized JSON APIs (user preferences, live chat, recommendations) are rarely that cacheable; they require edge-caching strategies or precomputed snapshots. So, the 90% figure is an achievable and realistic target mostly for the media plane - hitting the same ratio for API calls requires different techniques.
Why Multi-CDN Architecture Is Essential
Large streaming platforms never depend on a single CDN provider. If that provider experiences degradation or an outage, the entire platform is at risk. Instead, platforms use multi-CDN architectures - distributing traffic across multiple CDN providers simultaneously. A routing system continuously monitors latency, error rates, and network congestion. If one CDN degrades, traffic automatically shifts to another.
Key CDN Technical Details for Live Streaming
Several technical factors drive CDN efficiency in live sports:
- HLS/DASH Segment Duration & ABR: Live video is delivered as a sequence of media segments. Shorter segments (e.g., 2s) reduce latency and improve micro-buffering but increase HTTP request frequency. Longer segments reduce request overhead but slow bitrate switching. Teams tune segment size and ABR ladders to balance Quality of Experience (QoE), CDN cache efficiency, and tail latency.
- Player Tokenization & Auth Caching: To avoid a database hit for every play request, CDNs use signed URLs or short-lived JWTs issued at the auth edge. The player sends the token; the CDN validates the signature locally, eliminating synchronous DB validation for each segment request.
- TTL Tradeoffs & Cache Key Design: Longer CDN TTLs improve cache hit ratios but risk staleness for personalized content. Engineers use careful cache key design (chunk URL + quality + geography) and selective TTLs: long for media segments, short or conditional for personalization APIs.
- Write Buffering & Async Pipelines: Non-critical writes - view counters, analytics events - are buffered into message systems like Kafka or Pulsar and processed asynchronously, keeping the playback path synchronous and lightweight.
- HTTP/2 and HTTP/3 (QUIC): Modern streaming stacks adopt HTTP/3 on CDN-to-client paths to reduce handshake overhead and head-of-line blocking, improving user-perceived performance under congested networks.
The Database Problem at Internet Scale
Even with heavy CDN caching, some requests reach backend services - authentication tokens, playback authorization, and session management. With 325,000 origin requests per second and only 10% requiring database access, that still produces roughly
32,500 database queries per second. Handling this requires:
- Database replication across multiple regions
- Sharding strategies to distribute query load
- Aggressive read caching with Redis or Memcached
- Asynchronous processing pipelines for non-critical writes
Databases are often the most fragile component in the architecture, which is why engineers invest enormous effort protecting them.
Why Autoscaling Alone Is Not Enough: Pre-Scaling for Match Day
Cloud autoscaling handles gradual traffic increases well, but it has a critical limitation for live sports: it takes
minutes to provision new capacity - and a synchronized spike can overwhelm systems in
seconds. Engineering teams therefore combine several approaches:
- Pre-warmed read replicas: Capacity is provisioned before the match begins, not reactively.
- Vertical scaling / instance reservations: Critical DB nodes are reserved at larger instance sizes during match windows.
- Distributed SQL / NewSQL engines: Tools like CockroachDB, Spanner, and Yugabyte simplify multi-region replication and faster failover.
- Spot capacity with fallback: Non-critical components use spot instances with graceful fallback paths.
Match-day planning typically means pre-provisioning all critical capacity and relying on autoscaling only for smaller, non-critical components.
Client-Side Controls: Feature Flags and Graceful Degradation
Many mitigation strategies are implemented directly inside the mobile application. One powerful mechanism is feature flags - toggles that allow engineers to disable non-critical functionality instantly during traffic spikes. Personalized recommendations, interactive widgets, and social features can be turned off without affecting the video stream.
Combined with graceful degradation - where the app silently disables an unavailable service rather than showing an error - and client-side controls like exponential backoff and retry ceilings, the system pushes decision-making to the edge and reduces unnecessary origin load.
Panic Mode: The Final Safety Net for Streaming Infrastructure
Despite all preparation, unexpected failures can occur. Platforms prepare a final fallback mechanism known as panic mode. In panic mode, the system stops serving dynamic responses and instead delivers pre-generated static snapshots - scorecards, player data, metadata - directly through CDN caches. By switching to static responses, backend load drops dramatically while the video stream itself remains alive.
Match Day: The War Room & The Engineers Behind It
During major matches, engineering teams operate from a centralized war room, monitoring real-time dashboards displaying:
- CDN cache hit ratios
- API request rates and error rates
- Database CPU utilization
- Service latency and SLO compliance
If anomalies appear, mitigation strategies activate immediately - traffic rerouted between CDNs, feature flags toggled, cache TTLs extended. This coordinated
SRE response is what allows the system to survive extreme synchronized spikes.
The Invisible Champions: Engineers Behind the Stream
When the match ended, the spotlight belonged to the players. Sanju Samson's performance defined the tournament. Jasprit Bumrah delivered the decisive moment. India lifted the trophy. But another group of professionals quietly ensured 65 million fans could witness that moment together:
- The DevOps engineers who provisioned infrastructure
- The SREs who held SLOs through every spike
- The system designers who planned the architecture months in advance
When millions pressed play at the exact same second, their systems held strong.
Learn the Engineering Behind Internet-Scale Systems at CodeKerdos
At
CodeKerdos, we focus on exactly the real-world skills required to design and operate systems at this scale. Our programs teach practical expertise in:
- DevOps engineering & CI/CD pipelines
- Cloud infrastructure on AWS, GCP, and Azure
- Kubernetes and container orchestration
- Distributed system design and microservices architecture
- Observability, monitoring, and alerting at scale
- Site Reliability Engineering (SRE) principles and practices
Instead of focusing only on theory, we explore the architectures used by real platforms serving millions of users - the same kind of system design that kept JioHotstar alive for 65 million cricket fans.
Because the next time millions of people open an app to watch a match-winning moment, someone must design the system that keeps the stream alive. That engineer could be you.
👉 Learn more about the program here